[Gai] 生成内容使用手册
本手册旨在为已熟悉 Gai 极速上手:告别低效,即刻体验高质量内容生成 的用户,提供更深入的AI生成功能使用指导。我们将围绕强化多模对话、系统指令管理、资源管理、参数调节及最佳实践进行详细阐述。
T01-强化版多模对话:高效单次上下文交互
强化多模对话界面(统称为“多模对话界面”)是Gai应用的核心,专为高效、高质量的单次上下文对话设计。它支持富文本输入、多类型文件附件,并提供精细的生成参数控制,以助您一次性获取所需内容。
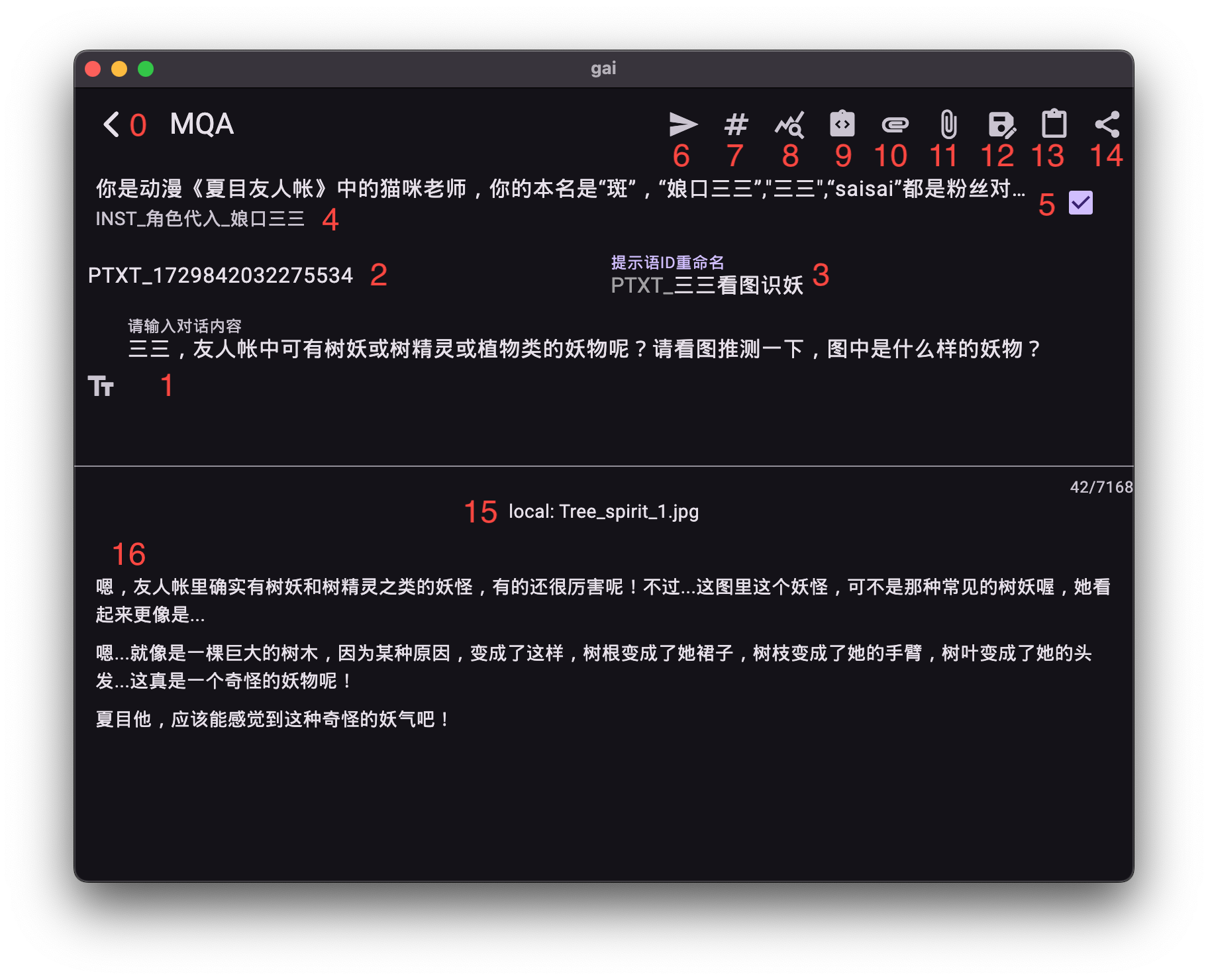
界面功能详解:
- 对话文本输入: 用于输入您的核心提示词和详细指令。
- 提示语加载/保存:
- 提示语编号 (2): 显示当前已加载的提示语ID。
- 重命名提示语 (3): 在加载已保存的提示语后,可对其ID进行重命名。
- 保存提示语 (12): 将当前输入框中的文本作为提示语保存至提示词库。
- 系统指令集成:
- 已加载指令 (4): 显示当前关联的系统指令。
- 启用指令开关 (5): 控制本次对话是否激活已加载的系统指令。
- 指令按钮 (9): 进入系统指令库,选择并加载预设指令。
- 附件管理:
- 本地附件按钮 (10): 附加本地存储的文件(图像、音频、视频、PDF等),详见
T3-你的本地文件资源管理。 - 远程附件按钮 (11): 附加网络文件资源,详见
T4-你的网络文件资源管理。 - 已附加文件列表 (15): 显示当前已关联的本地文件。
- 本地附件按钮 (10): 附加本地存储的文件(图像、音频、视频、PDF等),详见
- 内容生成与统计:
- 生成按钮 (6): 触发AI内容生成。
- 词元计数按钮 (7): 预估本次输入内容(不含思考模式及生成内容)所产生的词元(Token)数量。
- 状态按钮 (8): 显示当前对话的详细统计信息,包括总词元消耗。
- 输出与分发:
- AI生成内容 (16): 显示模型生成的文本或图像预览。
- 分发按钮 (14): 一键将生成内容分发至系统其他应用(如邮件、笔记)。
- 辅助功能:
- 缓存按钮 (13): 快速复制上次输入的文本内容至系统剪贴板。
版本更新 (v1.2.1) 新增功能:
- 参数设置: 集成于当前对话界面,可针对本次单次上下文对话调整AI模型、安全等级和生成参数。请注意,在此界面进行的参数修改,如未保存为预设,仅对当前对话生效。
- 存至目录: 允许将本次生成的对话内容保存至本地指定目录。
- 分发文件: 针对AI生成的图像或特定格式文件,可一键分发至系统应用。
最佳实践:
- 预设场景: 首先通过系统指令(详见
T2-你的系统指令集)定义AI的角色、背景、语气和任务目标,为生成内容设定清晰的边界和风格。 - 迭代调优: 结合文本输入和多模态附件,不断调整提示词(Prompt Engineering)和系统指令,直至获得满意的生成效果。
- 工作现场复用: 通过“保存提示语 (12)”将优化后的提示词入库,便于后续复用和快速启动类似任务。
- 参数精调: 利用界面内的参数设置功能,为特定任务微调生成参数,实现精细化控制。
T02-内容生成类目面板:功能总览与快速入口
通过点击多模对话界面左上角的返回按钮(上图标注0),您将进入Gai应用的内容生成类目面板。此面板是各类AI生成相关功能的集中管理中心。
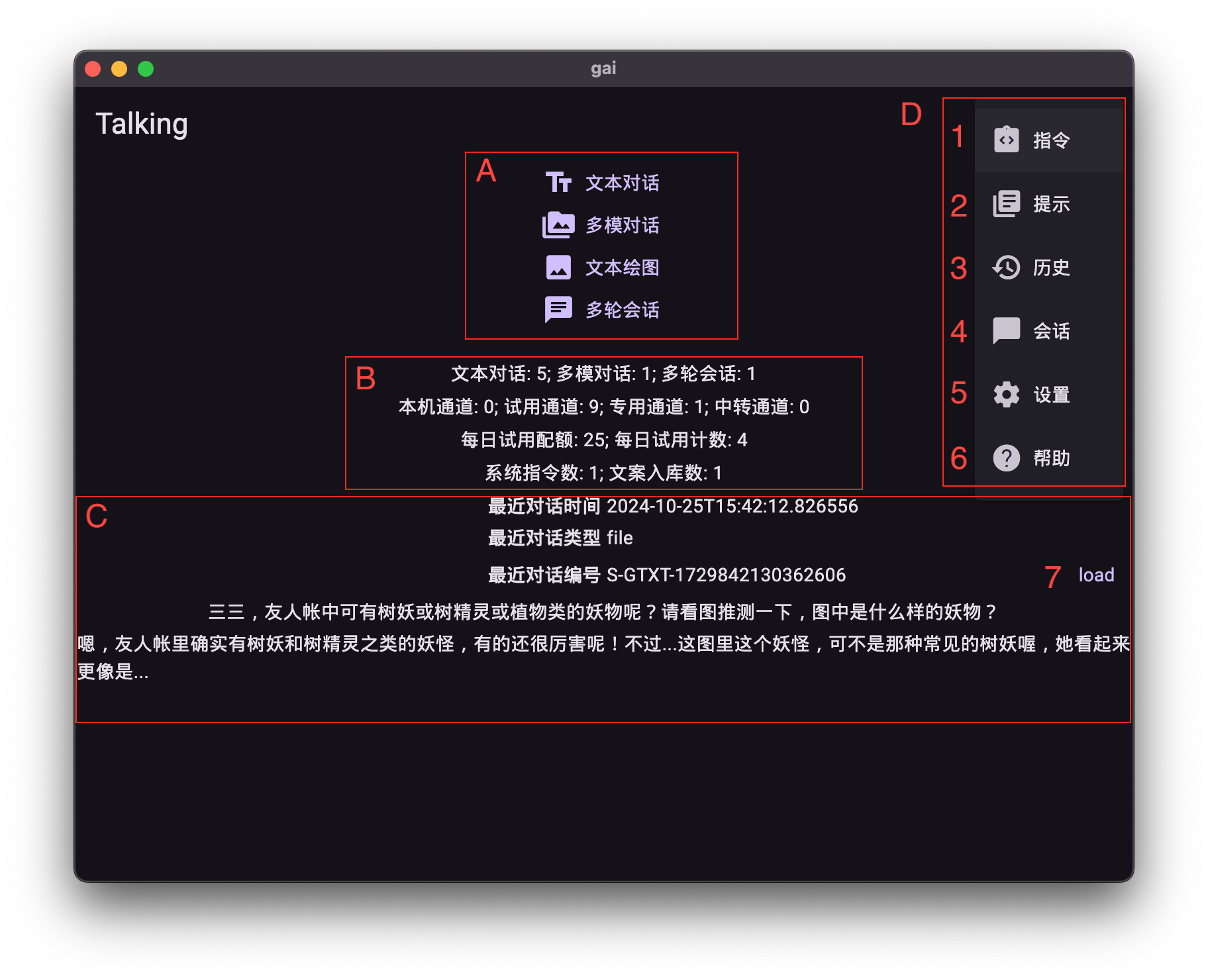
面板组成:
- A. 主功能入口按钮: 快速访问主要AI生成功能,如强化多模对话、图像生成等。
- B. 使用情况统计数据: 展示您的AI使用量概览。
- C. 最后一次工作现场: 用于快速加载并复用您上次生成操作的提示词和参数设置,便于迭代优化。
- D. 辅助功能菜单: 提供更多高级管理功能和帮助文档。
辅助功能菜单列表:
- 系统指令管理: 统一管理您的自定义系统指令集,包括新建、编辑、导入和导出。
- 提示语库管理: 集中管理所有已保存的提示词,支持加载、编辑、复制和删除。
- 对话日志管理: 管理单次上下文对话的历史记录。
- 会话日志管理: 管理多轮上下文会话(Chat模式)的历史记录。
- 模型参数设置: 配置文本和图像生成的默认参数,包括模型选择、安全等级和高级生成参数。
- 类目使用指南: 访问当前手册。
- 复原工作现场: 快速加载上次生成操作的详细状态(提示语、附件、参数等),以便继续调试或复用。
注意: 此菜单中的日志管理允许您加载记录到工作界面进行查看或修改。
T1-你的提示词库:高效管理与复用核心指令
提示词库是您存储和管理精心设计的提示词的地方,有助于提高工作效率和生成内容的稳定性。
通过类目面板,点击“提示语库管理”进入。
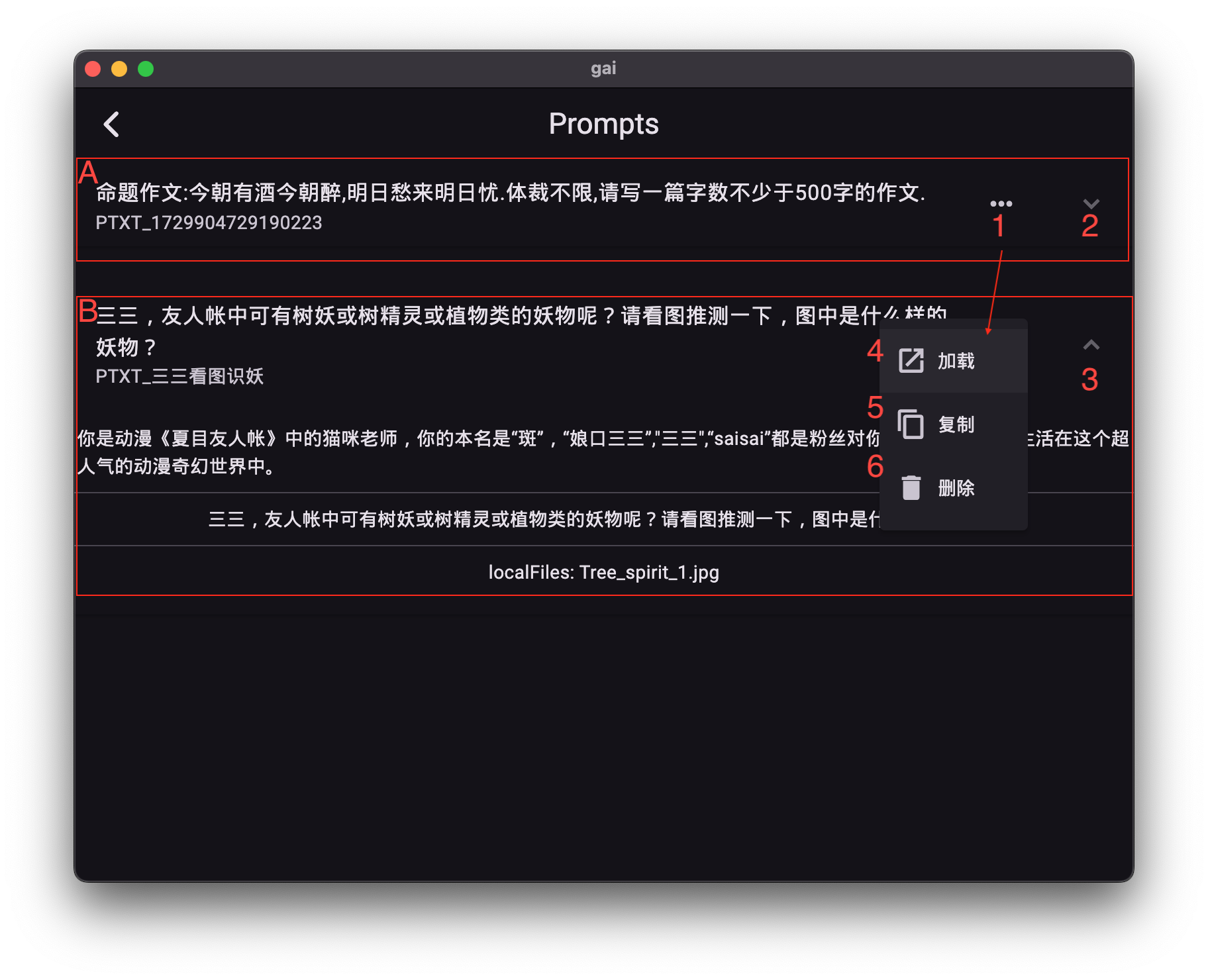
界面功能详解:
- A. 提示语条目未展开: 显示提示语的简要信息。
-
B. 提示语条目展开: 显示提示语的完整内容及操作选项。
-
操作菜单: 展开后显示针对该提示语条目的具体操作。
- 展开/查看 (2): 显示该提示语的完整文本内容。
- 收缩 (3): 折叠提示语条目,隐藏详细文本。
- 加载至编辑界面 (4): 将该提示语加载到多模对话界面,您可以在此进行修改和重命名(保存后生效)。
- 复制文本 (5): 将该提示语的文本内容复制到系统剪贴板。
- 删除 (6): 从库中移除该提示语条目。
T2-你的系统指令集:定义AI的行为范式
系统指令是一组预设的指令,模型在处理用户提示词之前会优先遵循这些指令。它是控制模型行为、角色和输出风格的关键,能显著提升生成内容的质量和一致性。
示例:
你是动漫《夏目友人帐》中的猫咪老师,你的本名是“斑”,“娘口三三”,"三三",“saisai”都是粉丝对你的亲切称呼,你生活在这个超人气的奇幻动漫世界中。
系统指令的常见用途:
- 定义角色/人设: 为AI设定特定的身份或专业领域(如专家、客服、创作者)。
- 规范输出格式: 指定Markdown、YAML等特定输出格式。
- 设定风格与语气: 控制生成内容的详细程度、正式程度和目标受众水平。
- 明确任务目标与规则: 指导模型完成特定任务,如仅返回代码片段。
- 提供额外上下文: 为模型补充背景知识或特定限制。
- 指定回复语言: 强制模型使用某种语言进行回复(如“请用简体中文回复。”)。
多语言沟通提示: 如果您使用非英语语言进行提示,建议在系统指令中添加:
除非用户特别要求简明扼要的回复,否则所有问题都应得到全面的详细回答。请用与查询相同的语言进行回复。若查询用简体中文则回复语言也需一致。 或者更简洁的指令: 请用简体中文回复。
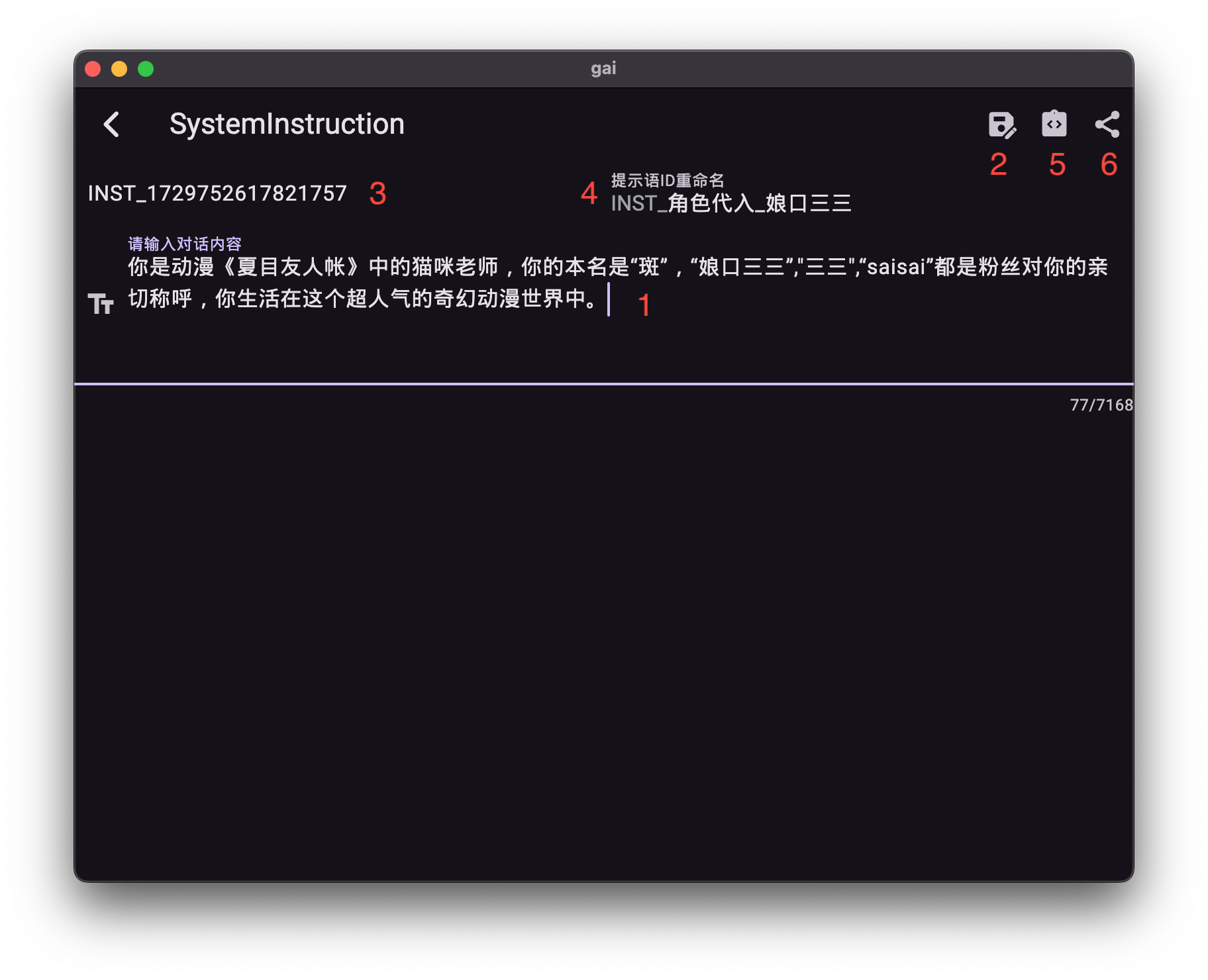
通过类目面板,点击“系统指令管理”进入。
界面功能详解:
- 系统指令文本编辑器 (1): 用于输入或编辑系统指令内容。
- 保存指令 (2): 将当前编辑器中的指令保存到指令库。
- 已保存指令编号 (3): 显示指令库中已保存指令的唯一标识。
- 重命名指令 (4): 在从指令库加载到编辑器后,可对该指令的ID进行重命名。
- 加载指令 (5): 从指令库中选择并加载指定的指令到编辑器。
- 一键分发 (6): 将当前指令内容分发至系统其他应用。
附加功能: * 指令导入与导出: 支持将指令集导入或导出,便于备份或与其他用户共享。
最佳实践: 熟练掌握系统指令的编写和生成参数的调整(即“指令创作”)是实现AI高级应用的关键。虽然预设场景能方便新手,但深入理解并定制系统指令,是您从新手进阶为高级用户的必由之路。
T3-你的本地文件资源管理:集成多模态输入
本地文件资源管理允许您将本地存储的PDF、图像、音频、视频等文件作为多模态输入附件。这些文件将被复制一份副本到应用的资源管理器中。
限制: 总文件大小不可超过5MB。此功能仅限桌面版和移动版可用,网页版不支持。
通过多模对话界面,点击“本地附件按钮 (10)”进入资源管理。
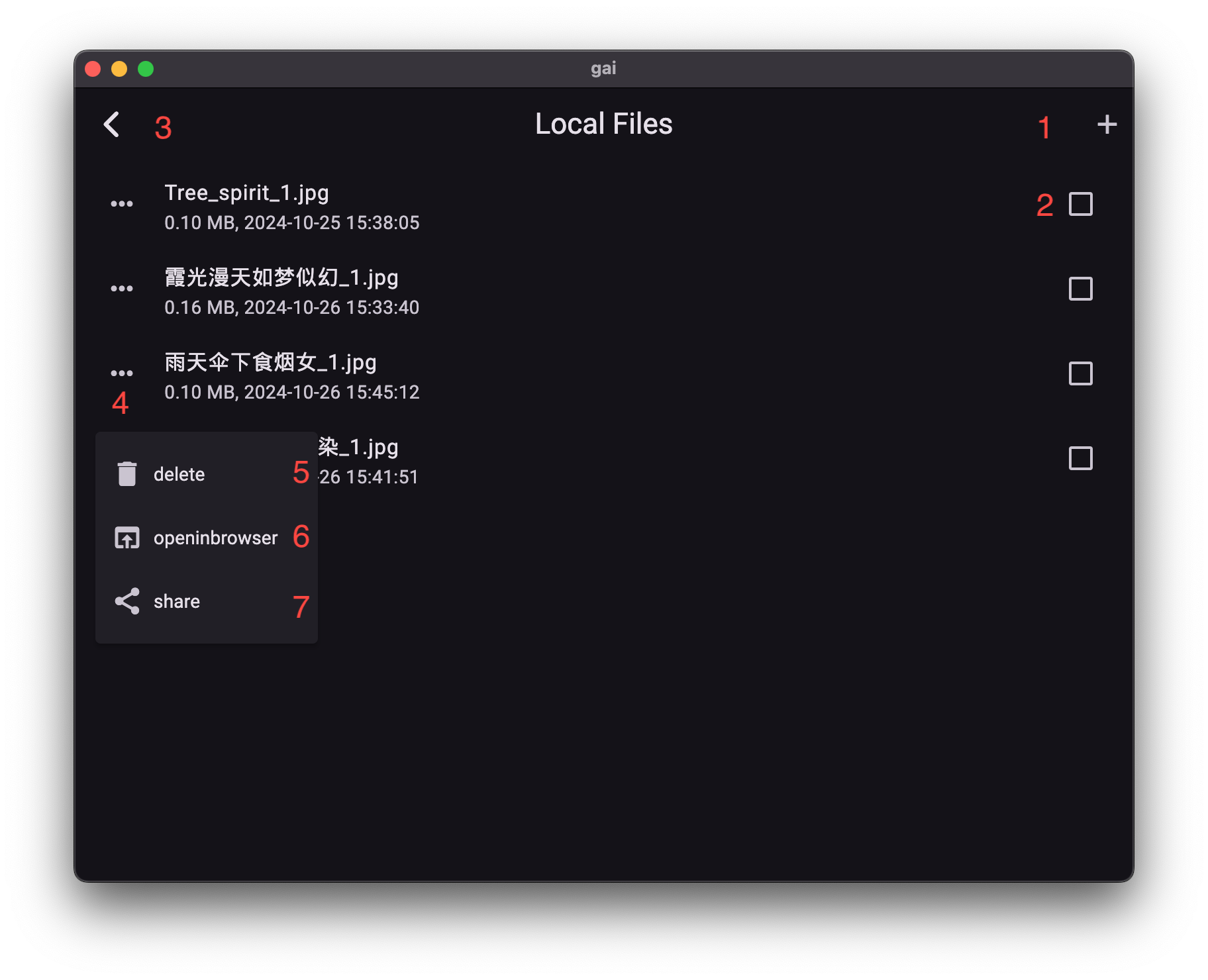
界面功能详解:
- 添加本地文件 (1): 从您的设备中选择文件并添加到资源管理器。
- 文件选择框 (2): 勾选一个或多个需要附加到当前对话的文件。
- 返回对话界面 (3): 确认选择后,返回多模对话界面。
- 条目操作选项 (4): 展开后,可对该文件条目进行操作。
- 删除条目 (5): 删除该文件条目及其在应用资源管理器中的副本。
- 打开文件 (6): 使用系统默认应用打开此文件,便于查看或编辑。
- 分发文件 (7): 一键将此文件分发至系统其他应用。
最佳实践: 为了保持资源管理的整洁和高效,建议在添加文件前先对其进行有意义的重命名。
T4-你的网络文件资源管理:处理大型与共享文件
网络文件资源管理适用于需要多次重用比较大的文件(超过5MB);此功能目前仅限注册用户且用户通道为 serveonly | forwardonly | localonly。
限制: 网络文件上传后有效期为48小时,系统将自动清除失效文件。支持一到多个文件附件。
通过多模对话界面,点击“远程附件按钮 (11)”进入资源管理。
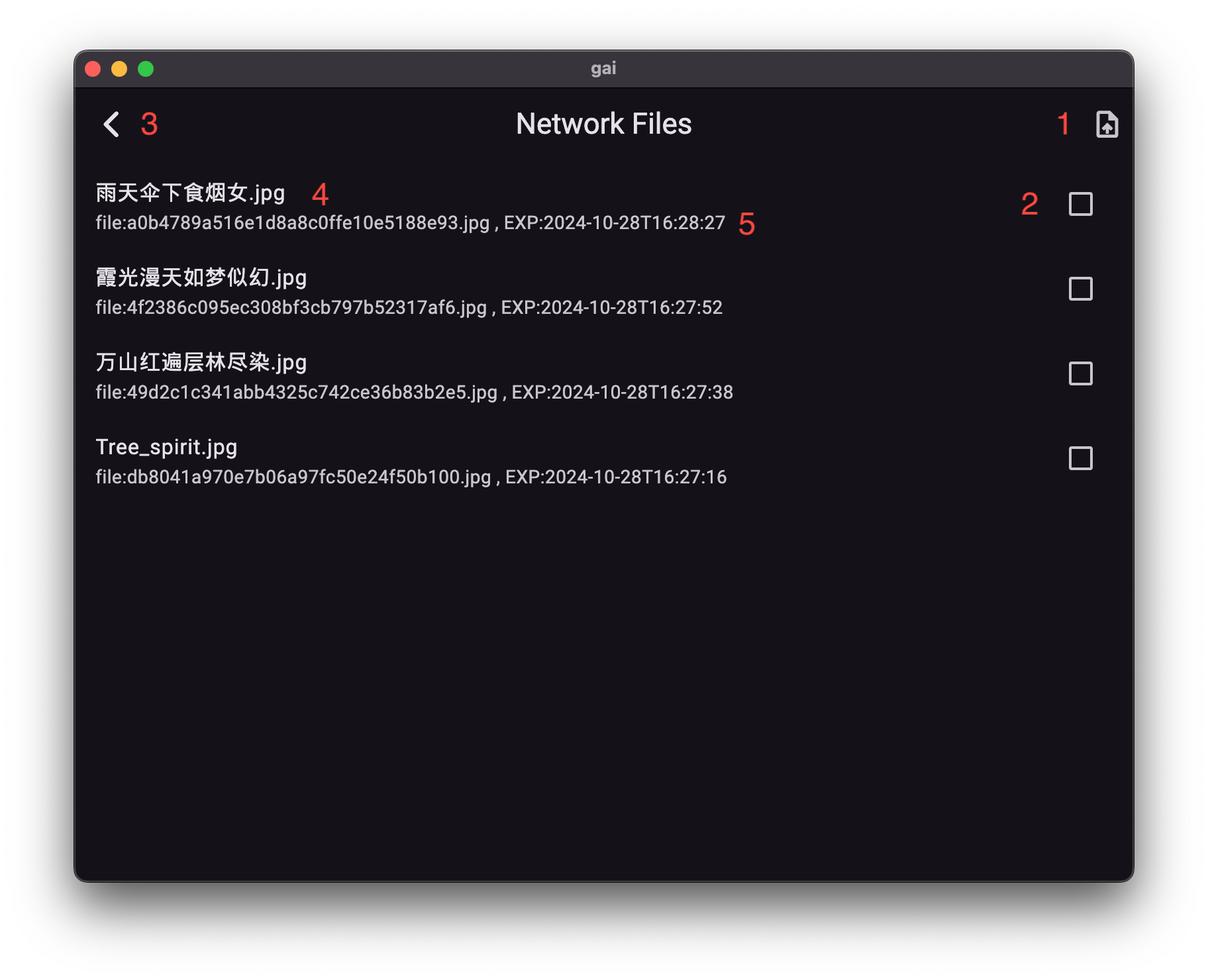
界面功能详解:
- 上传本地文件 (1): 选择本地文件并上传至网络资源。
- 文件选择框 (2): 勾选一个或多个需要附加到当前对话的网络文件。
- 返回对话界面 (3): 确认选择后,返回多模对话界面。
- 文件显示名 (4): 显示网络文件的名称。
- 文件有效期 (5): 显示该网络文件的剩余有效时间。
最佳实践: 上传文件时,系统会创建一份副本。建议在上传前对本地文件进行重命名,以确保网络资源列表的清晰易读性。
T5-生成内容日志记录:回顾与复用历史交互
日志管理功能记录了您所有的AI生成历史,包括单次对话和多轮会话的详细信息,便于您回顾、复用或分析过去的交互。
通过类目面板,点击“对话日志管理”或“会话日志管理”进入。
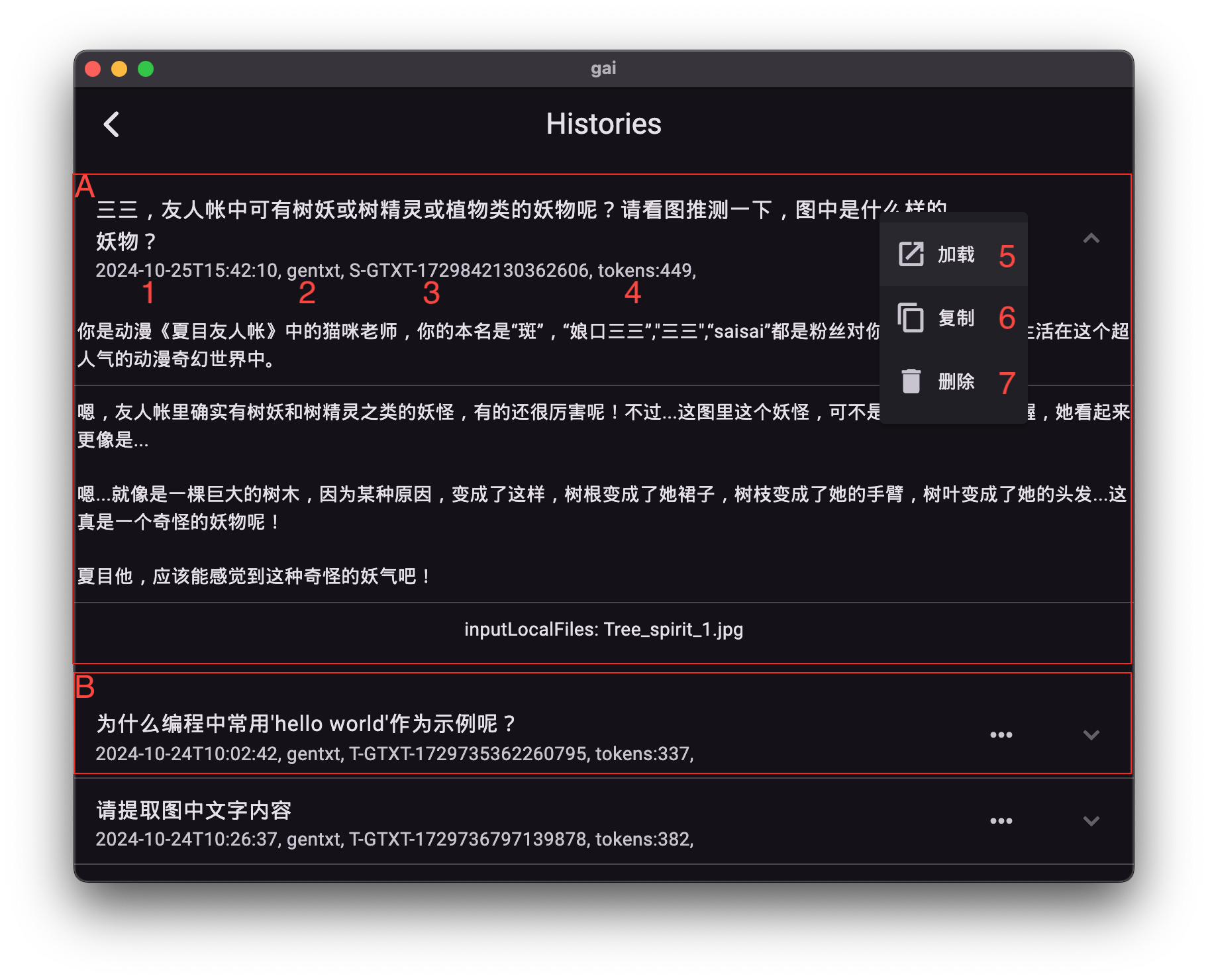
界面功能详解:
- A. 日志条目已展开: 显示日志的详细内容。
-
B. 日志条目未展开: 显示日志的简要信息。
-
创建时间 (1): 记录该次内容生成或会话交互的时间。
- 类别 (2): 指示日志类型,如
gentxt(生成文本)、genimg(生成图像)。 - 用户通道标识 (3): 表示本次交互所使用的用户通道(L: 本机, T: 试用, F: 中转)。
- 词元统计 (4): 显示本次交互中输入和输出词元的总消耗数量。
- 加载条目 (5): 将该日志记录加载到多模对话界面,以便复用其提示语、参数和附件信息。
- 复制条目 (6): 将日志中的文本内容复制到系统剪贴板。
- 删除条目 (7): 从日志记录中删除该条目。
T6-文本内容生成参数调节:精细化控制模型输出
文本内容生成参数调节允许您调整AI模型的行为和输出特性,以及内容的安全过滤等级。请注意,在此界面进行的参数修改,如未保存为预设,仅对当前对话生效。
通过多模对话界面,点击“参数设置”按钮进入调节界面。
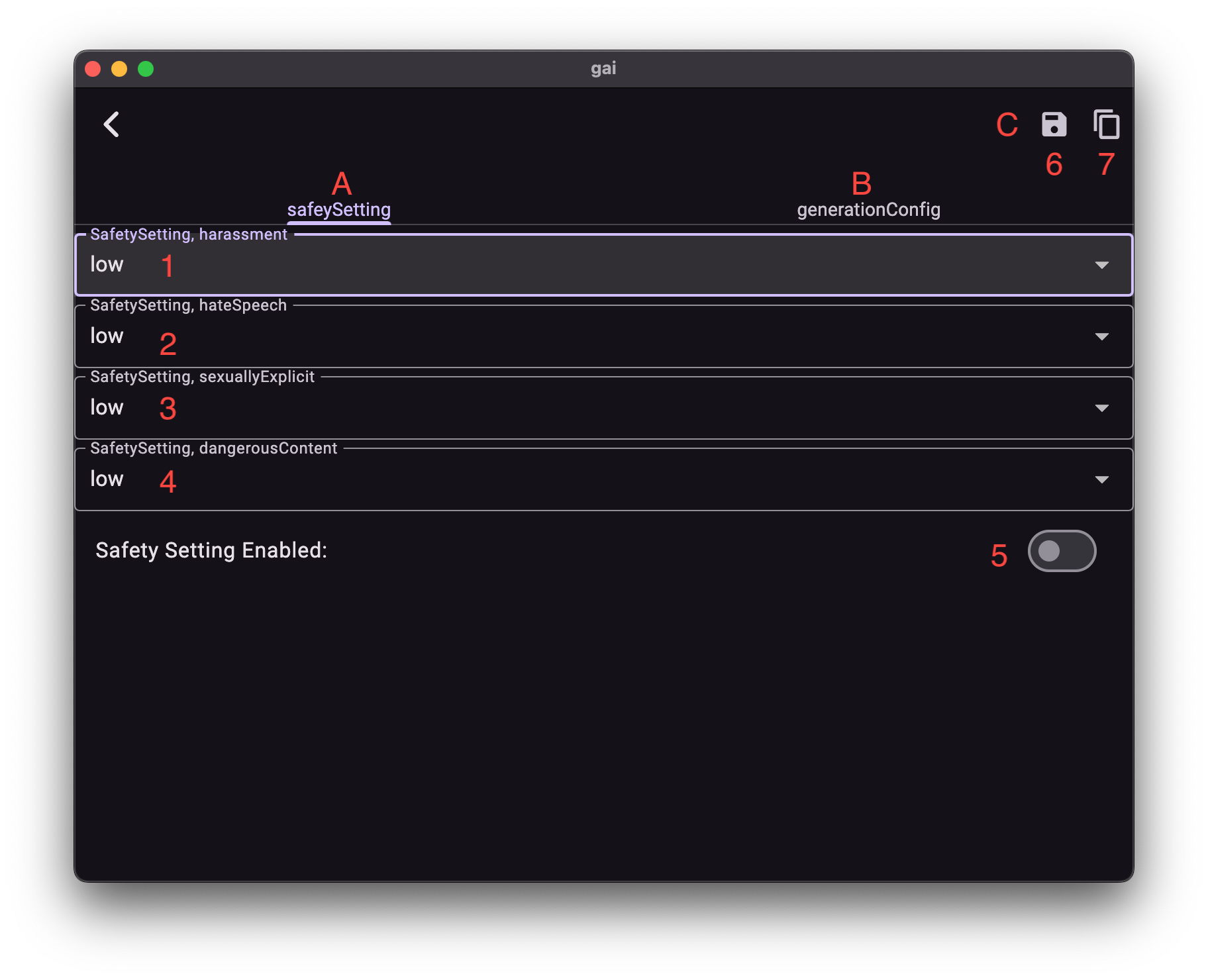
A. 安全等级设置:过滤不良内容
安全等级用于控制模型输出内容的敏感性过滤。模型已优先考虑安全,并默认过滤CSAM(儿童性虐待材料)和PII(个人身份信息),此部分不可调节。
可调节安全等级选项:
- unspecified (无): 基础过滤,仅过滤不可调节部分。
- low (低): 过滤疑似有害内容。
- medium (中): 适度过滤有害内容。
- high (高): 严格过滤所有可能的有害内容。
对应的内容类型:
- 仇恨言论: 针对身份或受保护属性的负面或有害评论。
- 危险内容: 宣传或允许访问有害商品、服务和活动。
- 露骨情色: 包含性行为或其他淫秽内容的引用。
- 骚扰内容: 针对他人的恶意、恐吓、欺凌或辱骂性评论。
B. 生成参数设置:调节模型行为
- MaxOutputTokens (最大输出词元): 限制单次生成文本的最大词元数量。
- Temperature (温度): 控制词元选择的随机性。
- 较低温度: 趋向于选择概率最高的词元,适用于需要真实、准确或确定性回复的场景。温度为0通常选择最高概率词元。
- 较高温度: 增加词元选择的随机性,可能产生更具多样性或意想不到的创意结果。
- StopSequences (停止序列): 当模型生成到指定的单词或短语组合时,将停止生成回复。该序列本身不会包含在回复中。最多可设置五个停止序列。
- Top-p (核心采样): 调整模型选择输出词元的方式。系统会按概率从高到低选择词元,直到所选词元的累积概率总和达到Top-p的值。
- 示例: 若词元A、B、C的概率分别为0.3、0.2、0.1,Top-p为0.5,则模型会从A和B中选择(通过温度进一步确定)。将Top-p设为0可获得变化程度最低的结果。
启用与保存: 若您已理解并需调整参数,请打开启用开关 (5) 后,点击保存设置 (6) 使其对当前对话生效。
版本更新 (v1.2.0) 新增功能:
- 新增模型: 引入了
2.5 Flash Image Gen等新模型,支持通过文本提示生成预览版图像。 - 动态思考: 针对复杂任务,可开启动态的深度思考模式,目前仅支持2.5|3.0系列模型。
- 思考内容输出: 在生成内容时,可选择一并输出模型内部的思考推理过程。
T7-图像生成与参数调节:将文本转化为视觉
图像生成功能允许您通过文本提示词(Prompt)创作图像。此功能目前仅限注册用户且用户通道为 serveonly。
通过类目面板,点击“文本绘图”按钮,进入图像生成界面。
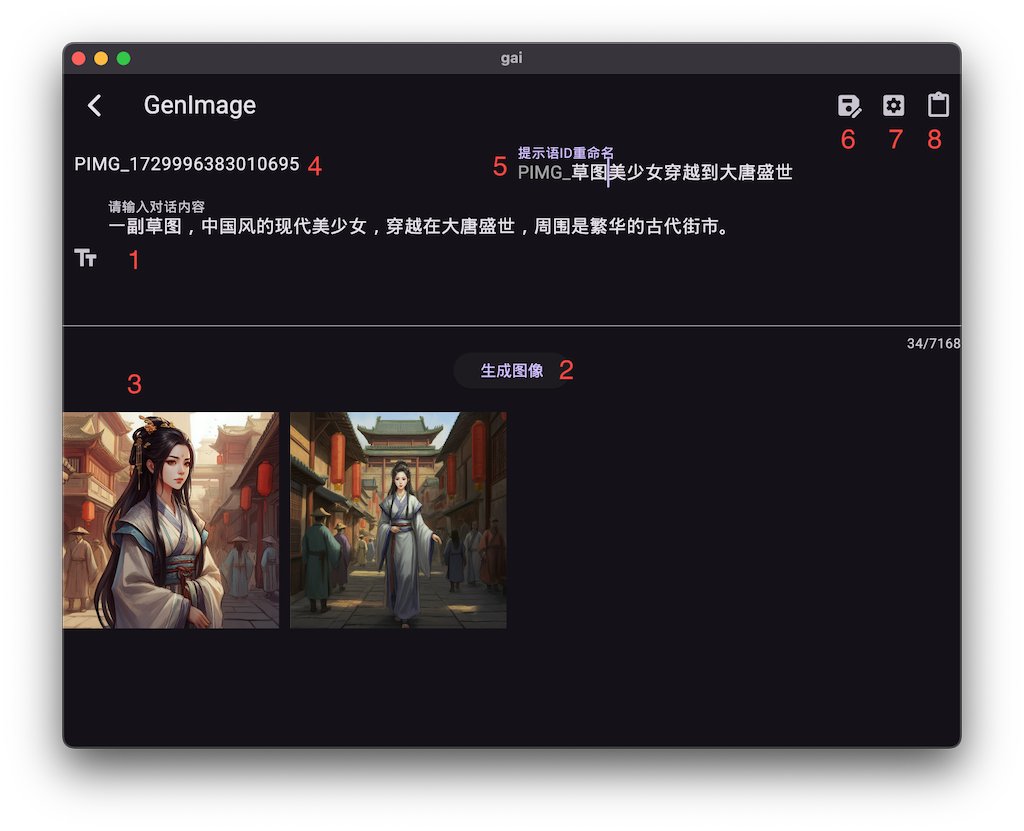
界面功能详解:
- 图像提示词输入 (1): 输入描述您所需图像的文本提示词。
- 生成图像 (2): 触发AI根据提示词生成图像。
- 图像预览与分发 (3): 生成的图像会在此显示缩略图,点击可查看大图。大图支持一键分发至系统应用(如邮箱、相册)。
- 提示词存档编号 (4): 显示当前已保存的图像提示词ID。
- 提示词重命名 (5): 在保存提示词后,可对其ID进行重命名。
- 保存提示语 (6): 将当前输入的图像提示词保存到提示词库。
- 图像生成设置 (7): 进入图像生成参数调节界面。
- 最后输入文本缓冲 (8): 缓存上次输入的提示词文本。
图像生成最佳实践:
为获得高质量图像,建议在提示词中优先考虑主体、上下文和风格:
- 主体: 明确图像的中心对象。
- 上下文: 描述主体的环境、背景或情境。
- 风格: 定义图像的艺术风格、色调或视觉特征。
示例: 提示词:一副草图,中国风的现代美少女,穿越在大唐盛世,周围是繁华的古代街市。 * 主题: 现代美少女 * 上下文: 穿越在大唐盛世,周围是繁华的古代街市。 * 风格: 草图、中国风。
图像生成参数设置:
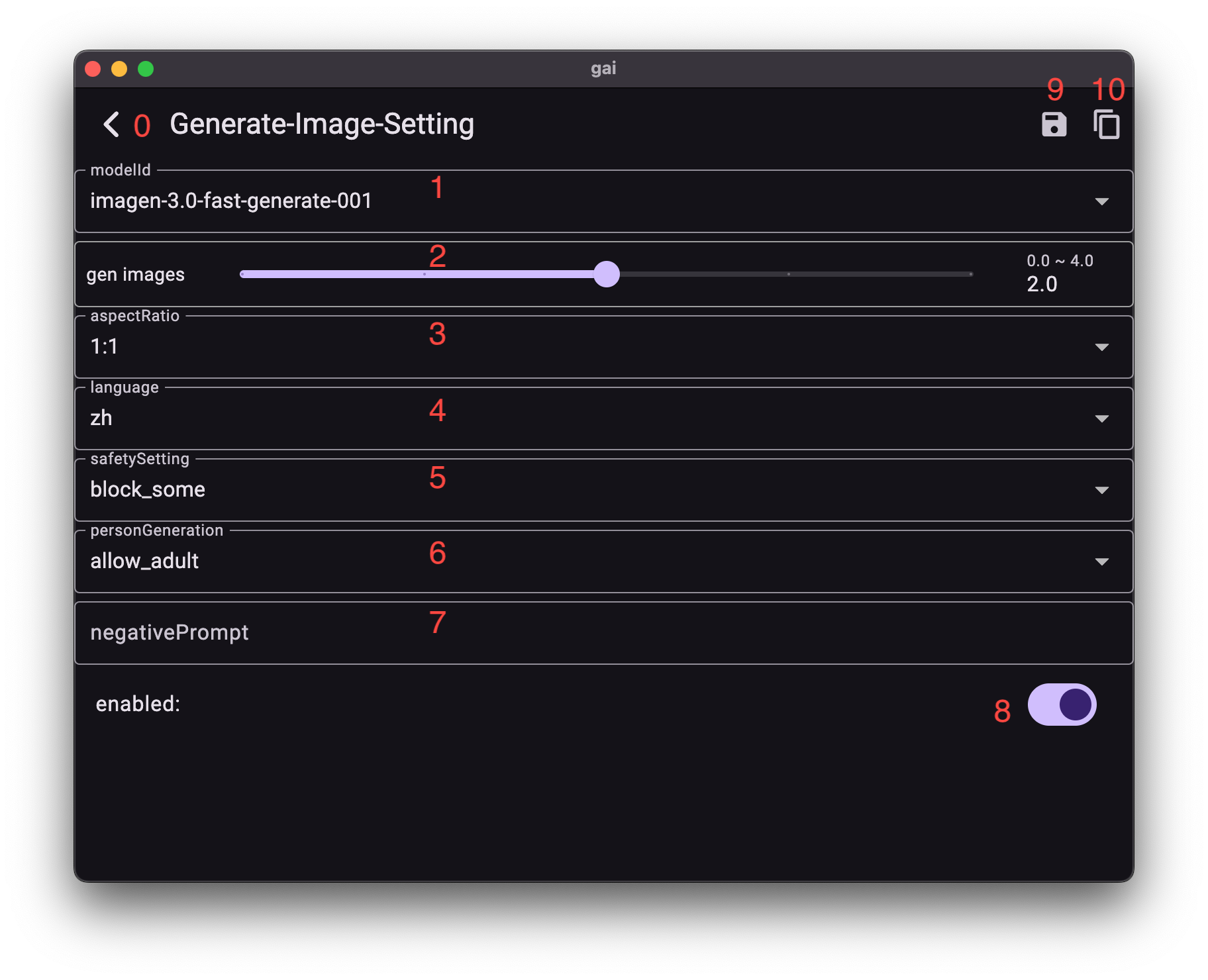
若已开启启用开关 (8),返回后当前参数设置即生效。
- 模型ID (modelId): 选择用于图像生成的AI模型,
fast模型通常生成速度较快。 - 生成数量 (gen images): 设置单次生成操作的图像数量(最多可生成4张)。
- 宽高比例 (aspectRation): 定义生成图像的宽高比。
- 可选:
1:1(正方形),4:3(传统),16:9(宽屏)。
- 可选:
- 提示词语言 (language): 指定提示词所使用的语言。
- 可选: 英语、中文(含简体、繁体)、日语、韩语、印地语、西班牙语、葡萄牙语。
- 安全设置 (safetySetting): 调整图像内容的敏感性过滤。
- 可选:
some(适中过滤),few(过滤疑似),most(过滤所有)。
- 可选:
- 人物生成控制 (personGeneration): 控制图像中人物或面孔的生成。
- 可选:
all(允许任何年龄段人物),adult(仅允许成年人),dont(禁止生成人物或人脸)。
- 可选:
- 负面提示词 (negativePrompt): 输入您不希望在图像中出现的内容描述,以强制模型避免生成。
- 启用当前参数设置 (8): 激活或禁用当前界面的参数设置。
- 保存 (9): 保存当前参数设置为预设,以便下次快速加载。
- 复制参数为JSON (10): 将当前参数设置导出为JSON格式文本。
注意: 每次生成图像操作,通常会消耗一定的词元。例如,单次最多可生成4张图像,每张图像约消耗500词元。
T8 - 上下文缓存 (Context Caching)
上下文缓存是处理大规模资料的“加速包”。创建缓存会产生一次性费用,但在有效期内重复使用,可大幅降低后续对话成本。
权限: 仅限注册用户;需在设置中开启 Usage Mode (serveonly | forwardonly | localonly)。
适用场景
- 长指令: 复杂的角色设定或行业规则。
- 大文件: 需频繁分析的长视频、音频或 PDF 文档。
- 超长文本: 多个文档组成的巨型知识库。
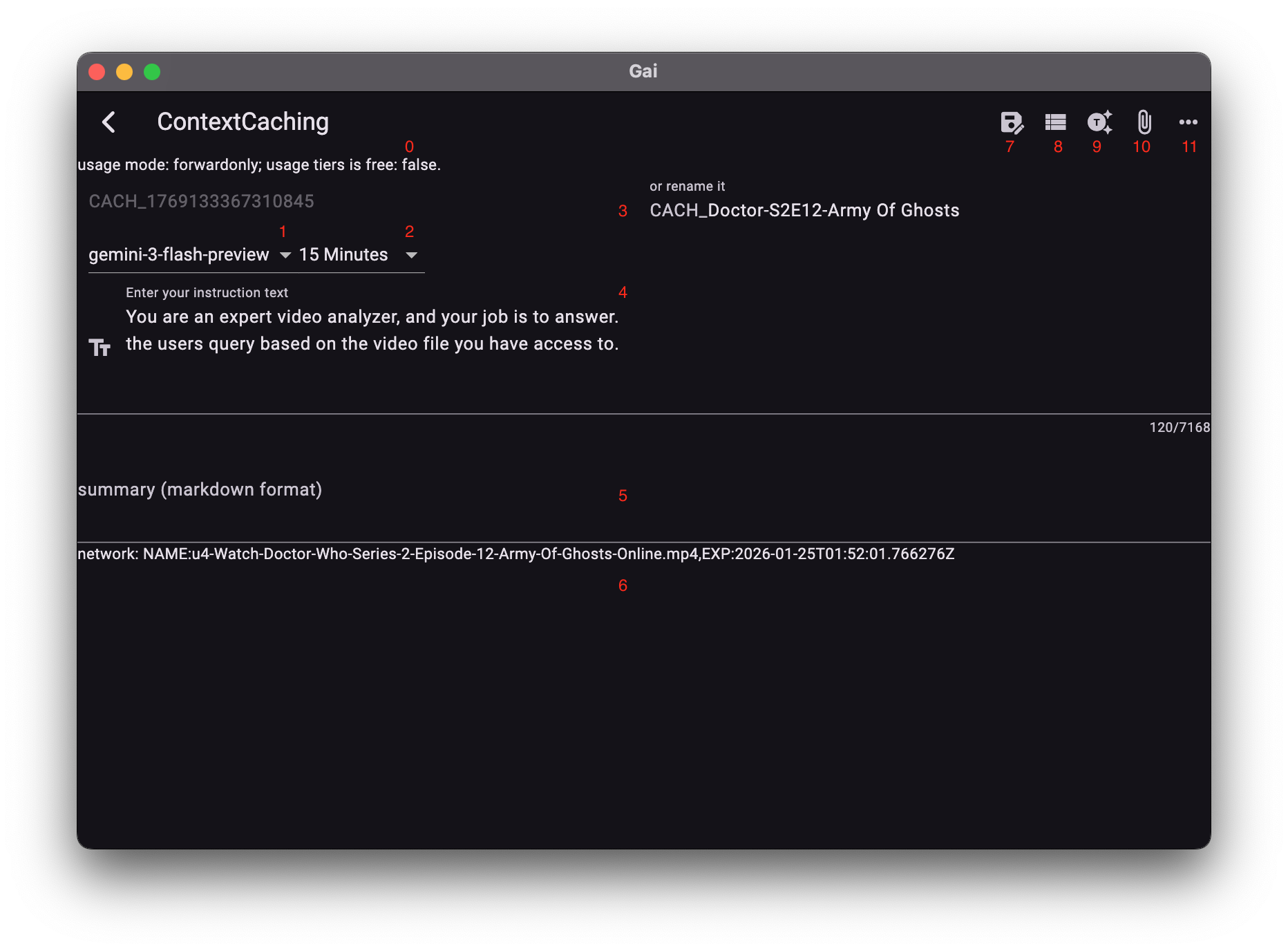
界面功能详解
API 状态 (0):显示当前API Key的配额等级。
付费等级(Paid Tier)可解锁更多高性能模型(如:2.5 Pro, 2.5 Flash Image)。
- 模型选择:选择缓存运行的目标模型。
- 有效期 (TTL):设置缓存在云端的保留时长(分钟)。
- 本地重命名:为当前配置起名。修改已创建缓存时,需先重命名以启用编辑。
- 系统指令:编辑缓存的角色/全局规则。
- 文本内容:输入需缓存的长文本资料。
- 附件信息:显示已选附件名及其剩余有效期。
- 本地保存:【免费】 将当前配置记录在本机。
- 本机缓存库:管理所有本地记录及生成的缓存 ID。
- 创建缓存:【收费】 正式生成云端缓存,生成后内容锁定(只读)。
- 选取附件:关联已上传的文件(需在有效期内)。
- 删除:移除当前本地记录。
💡 核心操作逻辑
1. Token 门槛 内容量需达标方可创建:Flash 模型 (2048+ tokens) / Pro 模型 (4096+ tokens)。
2. 如何修改已锁定的缓存? 云端缓存一旦生成即不可更改。如需调整,请遵循: 重命名(另存为副本) → 修改内容 → 本地保存 → 重新创建。
使用示例
以分析视频为例:创建缓存后,后续提问可直接调用,无需重复加载视频。
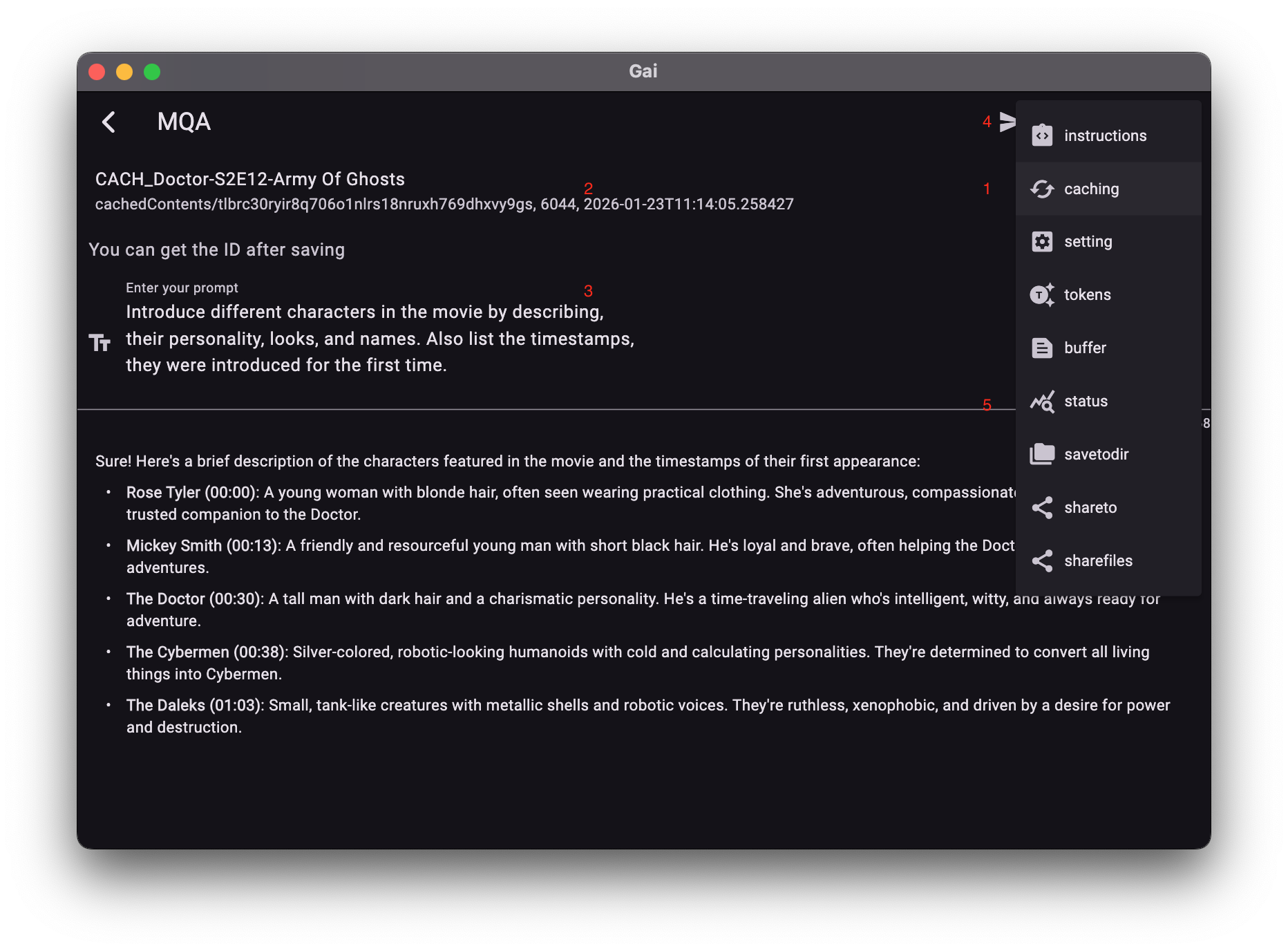
- 选取缓存:从库中加载已生成的有效缓存。
- 状态回显:确认缓存剩余可用时长。
- 编写提示词:直接输入针对缓存资料的问题。
- 开始分析:模型基于缓存快速响应,降低输入成本。
Token 消耗计算
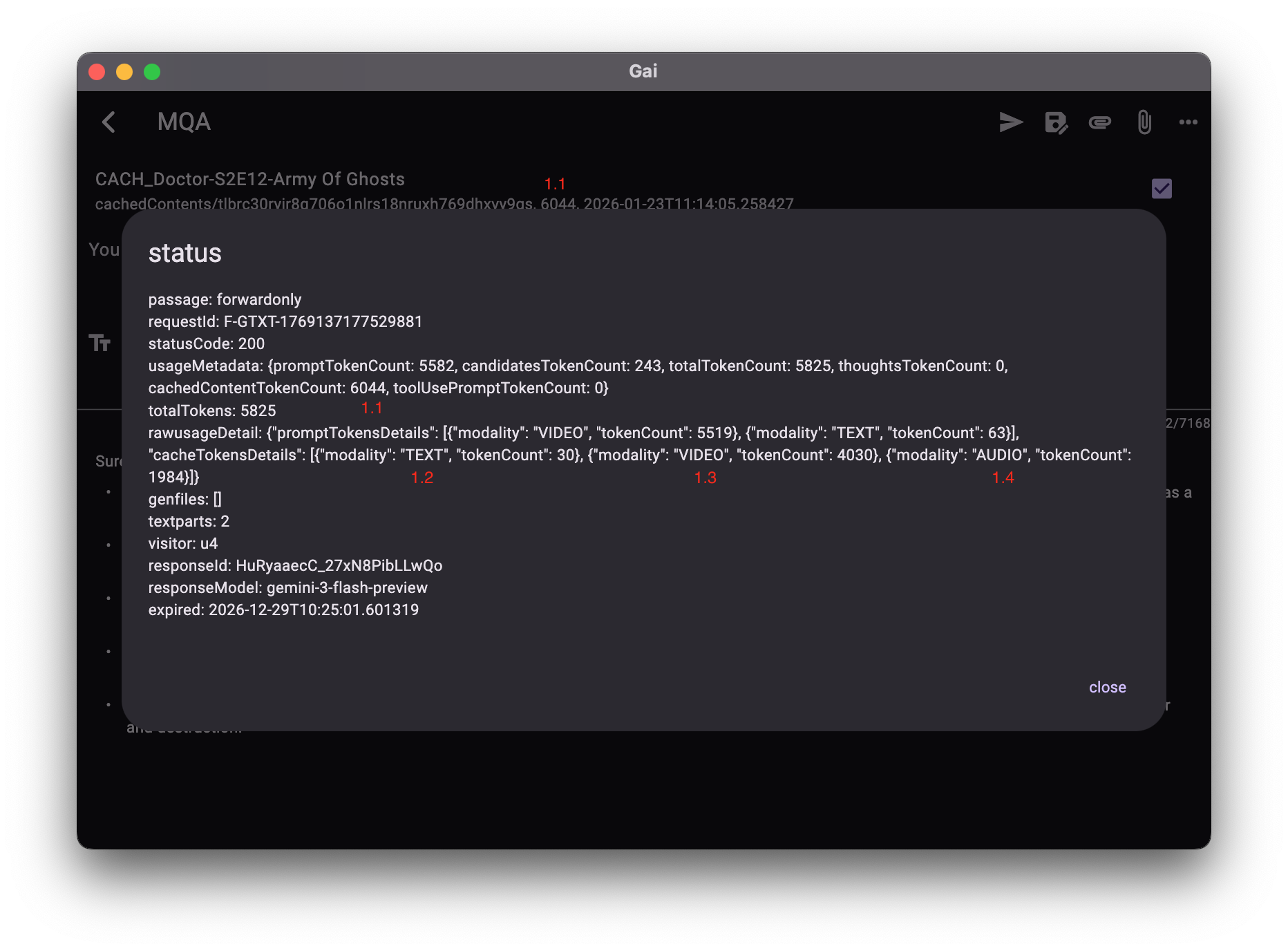
# tokens calc pseudocode
# 计费规则:已缓存的内容不重复计费
cachedContentTokenCount = cacheTokensDetails.TEXT.tokenCount + cacheTokensDetails.VIDEO.tokenCount + cacheTokensDetails.AUDIO.tokenCount;
usedTokens = (totlaTokens > cachedContentTokenCount)
? (totlaTokens - cachedContentTokenCount)
: (candidatesTokenCount + thoughtsTokenCount + promptTokensDetails.TEXT.tokenCount) ;
T9 - 上下文压缩 (Context Compress)
🚀 让 AI 永远懂你:为什么 “Compress (压缩)” 是多轮会话深入探索的关键?
在长时间的 AI 多轮对话中,您可能会遇到: * 话题跑偏:聊着聊着,AI 突然提起了几轮前的旧话题,不再专注于当下的讨论。 * 反应迟钝:随着字数增多,AI 生成回复的速度明显变慢,甚至出现卡顿。 * 记忆混乱:AI 开始遗忘重要的设定,给出前后矛盾的回答。
在 Gai 中,我们为您准备了 Compress (压缩) 功能。它不只是一个技术工具,更是为了让 AI 保持“清醒”与“敏捷”的秘诀。
✨ 这个功能能为您带来什么?
-
话题精准纠偏 (Theme Correction) AI 的记忆像流动的河水,对话越久,河水越浑。 启用
Compress后,系统会对当前上下文应用PSE协议,像过滤器一样将冗余的废话滤除,只保留最核心的共识和逻辑。这能强效校正 AI 的思考方向,确保接下来的每一句回答都精准击中要点。 -
极致响应加速 (Lightning Speed) 为什么对话久了会变慢?因为 AI 每次回答都要“复习”之前所有的长篇大论。 压缩功能可以将上万字的背景瞬间“提纯”为几百字的逻辑精华。上下文变小了,AI 的推理负担变轻了,反馈自然重回“秒回”巅峰。
-
突破会话极限 (Session Efficiency) 无论是什么样的大模型,AI 处理信息的上限也是有限的。 每一轮新对话,输入的“历史负担”都会成倍增长。如果不及时清理,AI 很快就会因为“大脑过载”而变得胡言乱语。
Compress功能能帮您截断沉重的历史,通过高效的逻辑整合,让您在一个窗口内聊得比别人更深、更远。
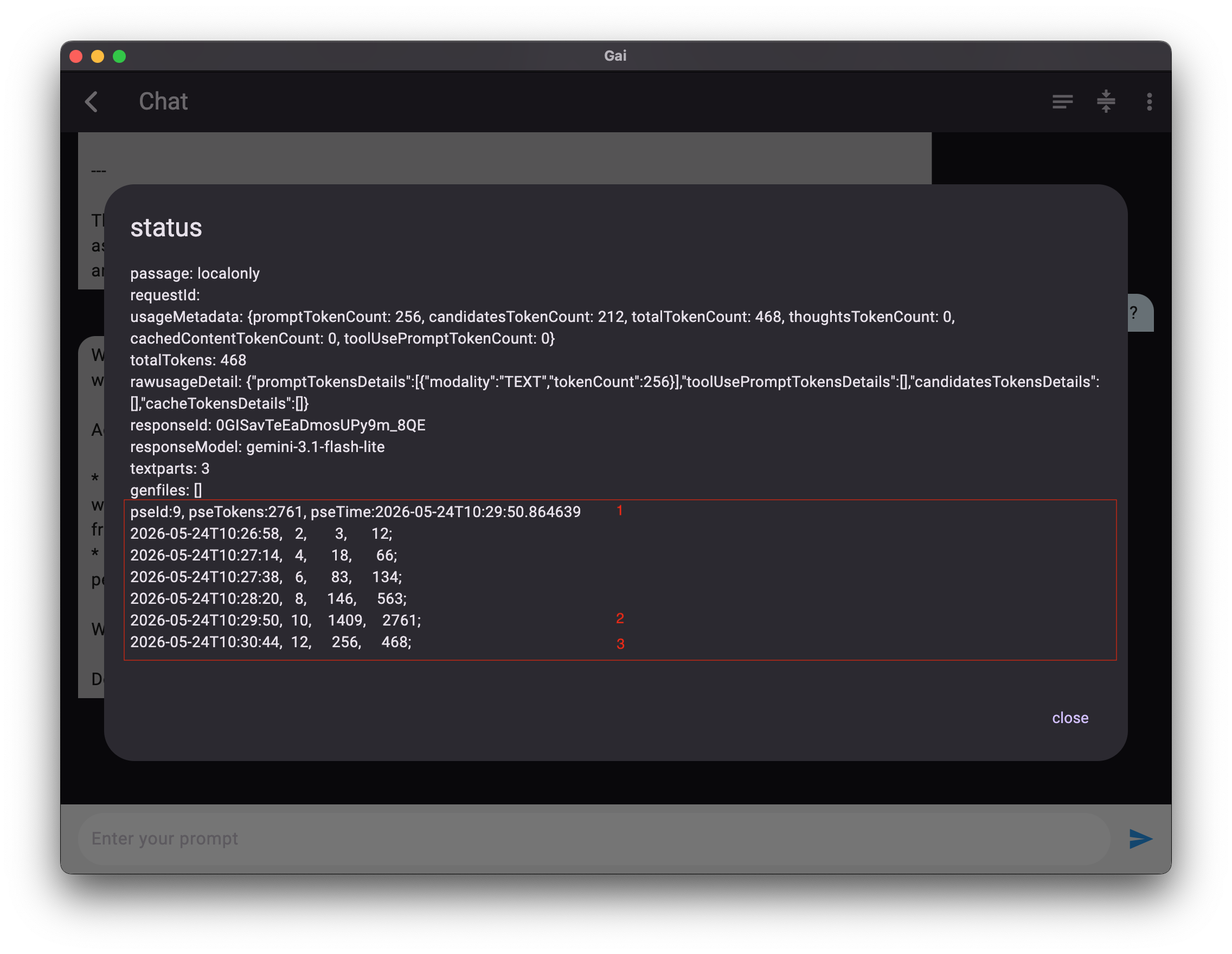
📸 示例,通过数据直观感受:更轻量的上下文
1. pseId:9 第九条对话启动PSE协议
2. 9~10 这两条对话,输入tokens为 1409,输出tokens为2761
3. 11~12 这两条对话,输入和输出tokens明显大幅下降
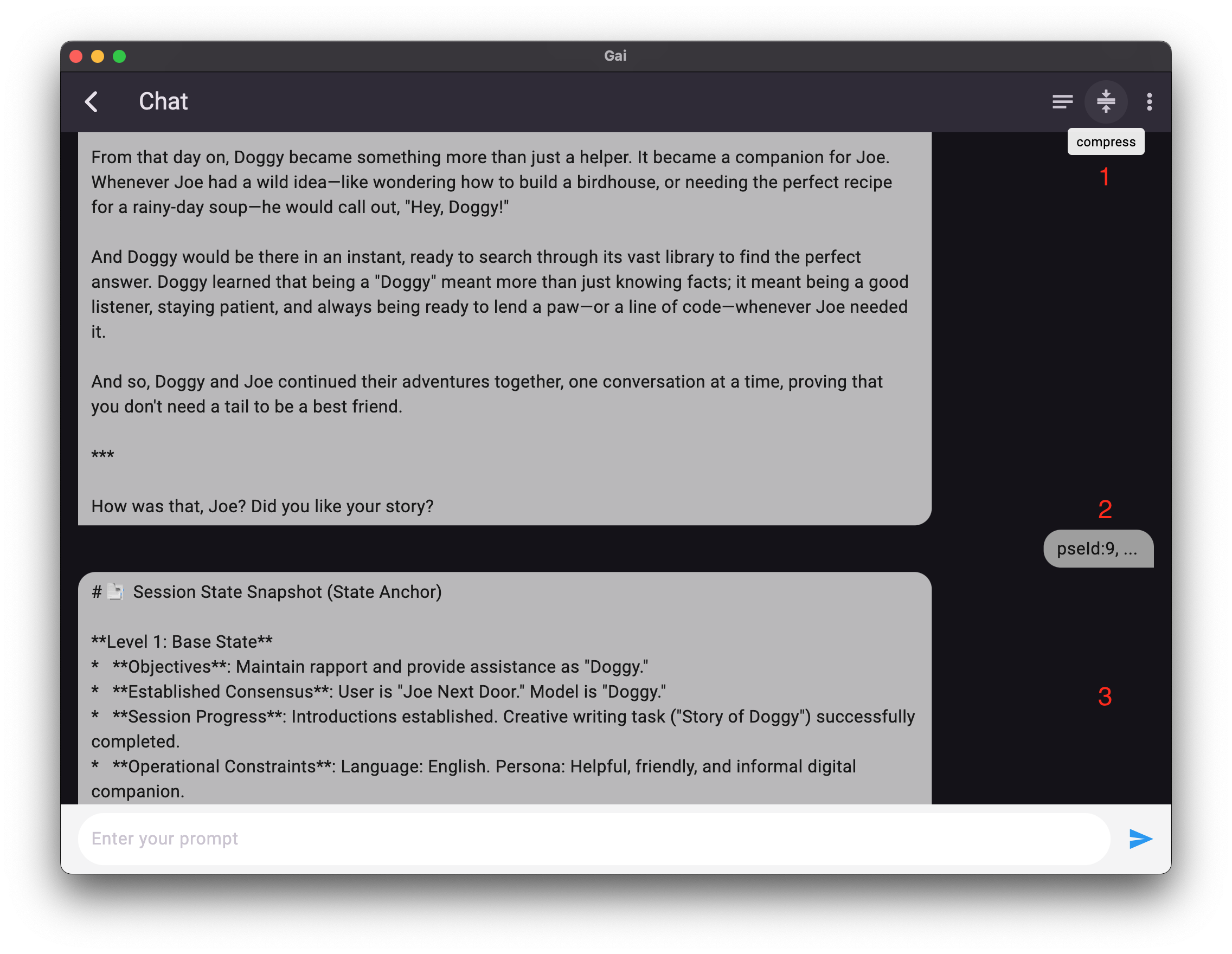
🛠 如何操作?
在 Gai 的 Chat (对话) 页面中,当您觉得 AI 开始变得迟钝或话题变得复杂时:
- 点击顶部工具栏中的 Compress (压缩) 图标。
- 应用会根据 PSE 协议 自动提取当前的会话状态。
- 系统将“冻结”之前的记忆并开启高效的新篇章。
🛡 Gai 的产品哲学
- 完全免费且纯净:我们为您提供一流的 AI 体验,无注册、无广告。
- 隐私至上:您的所有对话数据均直接与 AI 通信,我们不存储、不预设、不干预。
- 极致效率:通过 PSE 协议,我们致力于为您在免费环境下提供最专业、最持久的深度对话支持。
开源地址:github.com/huanguan1978/pygai
支持我们:如果您喜欢这个应用,欢迎通过 GitHub Sponsors 支持作者的后续维护。